Problème test unitaire

Christian Aucane
Dans le cadre de ma formation je dois faire une appli de recommendation de films qui utilise du Machine Learning ( j'ai choisi le KNN comme algo ), j'ai choisi de la faire avec django pour l'interface. Mon application fonctionne parfaitement, j'ai écrit les tests et dans mes tests j'ai une erreur incomprehensible qui se produit uniquement lors du test d'une de mes vues, je met mon code :
le code de mon test :
class ResultViewTest(TestCase):
def setUp(self):
self.factory = RequestFactory()
self.client = Client()
def test_not_allowed_request(self):
# Test GET request
request = self.factory.get(reverse('app:result'))
response = result(request)
# Check the returned status code and message
self.assertEqual(response.status_code, 405) # 405 for method not allowed
self.assertIn("Cette URL n'est pas accessible directement", response.content.decode())
def test_post_request(self):
# Test POST request
request = self.client.post(reverse('app:result'), data={
"age": "adult",
"languages": ["English"],
"duration": ["1"],
"filter": "genres",
"genres": ["Action"],
})
title = "Spider-Man 3"
nb = 5
recommendations_idx = list(range(51))
request.session = { # Mocked session data
"title": title,
"nb": nb,
"recommendations_idx": recommendations_idx
}
response = result(request)
# Check the returned status code
self.assertEqual(response.status_code, 200)
# Check if the correct template is used
self.assertTemplateUsed(response, 'app/result.html')
# Check if the context data is correctly added
self.assertIn("title", response.context)
self.assertIn("nb", response.context)
self.assertIn("recommended_films", response.context)
Le code de ma vue
def result(request):
"""The view for the result page"""
if request.method != 'POST':
response = HttpResponseNotAllowed(['POST'])
response.content = """
<h1>Cette URL n'est pas accessible directement</h1>
<p><i>Veuillez remplir le formulaire de la page d'accueil</i></p>"""
return response
# We get the choices in the form in 'data'
data = request.POST
# We get title, number of recommendations and index of recommended movies from the session
title = request.session.get("title")
nb = request.session.get("nb")
idx = request.session.get("recommendations_idx")
# We load recommendations with the indexes
df = utils.load_recommendations(idx)
# We store all the choices in a dict
choices = {"age": data.get("age"),
"languages": data.getlist("languages"),
"duration": data.getlist("duration"),
"filter": data.get("filter"),
"genres": data.getlist("genres"),
"actors": data.getlist("actors"),
"directors": data.getlist("directors")}
# We filter recommendations with the user choices
df = utils.filter_recommendations(df, choices, nb)
# We get the Series we need to use in the template
titles = df["movie_title"]
urls = df["movie_imdb_link"]
genres = df["genres"]
actors = df["actor_1_name"]
directors = df["director_name"]
# We store all in a list of dict contains datas for each movie
recommended_films = [{"title": title,
"url": url,
"thumbnail_url": utils.get_thumbnail_url(url),
"genres": ", ".join(genre.split("|")),
"actor": actor,
"director": director} for title, url, genre, actor, director in zip(titles,
urls,
genres,
actors,
directors)]
# We store all datas we need in the template in a dict
context = {"title": title,
"nb": nb,
"recommended_films": recommended_films}
# And we return the render of the template
return render(request, "app/result.html", context)
le code de mon fichier utils.py
import pandas as pd
import requests
from bs4 import BeautifulSoup
from project import settings
from sklearn.neighbors import NearestNeighbors
DATA_DIR = settings.BASE_DIR / "data"
def load_movies():
"""Function to load movies dataframe
Returns:
pd.DataFrame: A dataframe contains all movies
"""
# We load the dataframe from CSV file
df = pd.read_csv(DATA_DIR / "cleaned_data.csv")
# We fill empty values with an empty string ( Don't worry the dataframe is already cleaned ! )
df.fillna("", inplace=True)
return df
def load_recommendations(idx):
"""Function to load recommendations
Args:
idx (iterable): An iterable contains indexes of movies to load
Returns:
pd.DataFrame: A dataframe contains movies at the indexes in idx
"""
# We load the movies dataframe
df = load_movies()
# We return only the movies with an index in 'idx'
return df.iloc[idx]
def filter_by_age_category(df, age_category):
"""Function to filter the movies dataframe by age_category
Args:
df (pd.DataFrame): A movies dataframe
age_category (str): The age category to filter (possibles values : ["adult", "teenager", "child"])
Returns:
pd.Dataframe: The dataframe after filtering
"""
if age_category == "adult":
return df
elif age_category == "teenager":
return df[df["age_category"] != "adult"]
elif age_category == "child":
return df[df["age_category"].isin(["child", "unknown"])]
def generate_recommendations(title="", nb=5, age_category="adult"):
"""Function to generate recommendations using Machine Learning
Args:
title (str, optional): The title of the movie the user choosed. Defaults to "".
nb (int, optional): Number of recommandations the user want. Defaults to 5.
age_category (str, optional): A string representing the category of age. Possibles values : ["child", "teenager", "adult"]. Defaults to "adult".
Returns:
pd.DataFrame: A dataframe contains movies are recommended by the Machine Learning algorithm
"""
# we load the preprocessed and the movies dataframe
df_ML = pd.read_csv(DATA_DIR / "preprocessed_data.csv.gz")
df_movies = load_movies()
# We filter ML dataframe by age
df_ML = df_ML[df_ML.index.isin(filter_by_age_category(df_movies, age_category).index)]
# We rename the first column to idx
new_columns = df_ML.columns.tolist()
new_columns[0] = 'idx'
df_ML.columns = new_columns
# We fit the NearestNeighbors model
nn = NearestNeighbors(n_neighbors=nb * 10 + 1)
nn.fit(df_ML.drop("idx", axis=1))
# We get the index of the movie with his title, and we get the neighbors
idx = df_movies[df_movies["movie_title"] == title].index[0]
distances, indices = nn.kneighbors(df_ML[df_ML["idx"] == idx].drop("idx", axis=1))
# We get the indexes of the movies (except the first, it's the input movie)
indices = df_ML.iloc[indices[0, 1:]]["idx"].values
# And we load the recommendations in a dataframe
df_recommendations = load_recommendations(indices)
return df_recommendations
def filter_recommendations(df, choices, nb=5):
"""Function to filter recommandations by user choices
Args:
df (pd.DataFrame): A dataframe contains movies recommendations
choices (dict): A dictionary containing the user choices
nb (int, optional): The number of recommendations needed. Defaults to 5.
Returns:
pd.DataFrame: A dataframe contains the movies recommendations filtered
"""
# Filter by languages
languages = choices["languages"]
if languages:
df = df[df["language"].isin(languages)]
# Filter by time
durations = choices["duration"]
if durations:
temp_df = None
if "0" in durations:
mask = df["duration"] < 90
temp_df = pd.concat([temp_df, df[mask]])
if "1" in durations:
mask_1 = df["duration"] >= 90
mask_2 = df["duration"] < 120
temp_df = pd.concat([temp_df, df[mask_1 & mask_2]])
if "2" in durations:
mask_1 = df["duration"] >= 120
mask_2 = df["duration"] < 180
temp_df = pd.concat([temp_df, df[mask_1 & mask_2]])
if "3" in durations:
mask = df["duration"] >= 180
temp_df = pd.concat([temp_df, df[mask]])
if len(temp_df):
df = temp_df
# Sort selection criteria
filter_choice = choices["filter"]
# Sort by gender in choices
if filter_choice == "genres":
def sort_func(title_genres, choice_genres):
return title_genres.apply(lambda x: sum(1 for genre in x.split("|") if genre in choice_genres))
genres = choices["genres"]
if genres:
df = df.sort_values(by="genres",
key=lambda x: sort_func(x, genres),
ascending=False)
# Sort by actors in choices
elif filter_choice == "actors":
def sort_func(title_actors, choice_actors):
return title_actors.apply(lambda x: 1 if x in choice_actors else 0)
actors = choices["actors"]
if actors:
df = df.sort_values(by="actor_1_name",
key=lambda x: sort_func(x, actors),
ascending=False)
# Sort by director in choices
elif filter_choice == "directors":
def sort_func(title_director, choice_directors):
return title_director.apply(lambda x: 1 if x in choice_directors else 0)
directors = choices["directors"]
if directors:
df = df.sort_values(by="director_name",
key=lambda x: sort_func(x, directors),
ascending=False)
return df.iloc[:nb, :]
def get_thumbnail_url(url):
"""Function to scrap IMDB website and get the movie image URL
Args:
url (str): The url of the movie
Returns:
str: The url of the movie image
"""
# We modify url to get the photo gallery webpage
url = "/".join(url.split("/")[:-1]) + "/mediaindex?ref_=tt_ov_mi_sm"
response = requests.get(url) # We get the HTML response of the url
soup = BeautifulSoup(response.text, "html.parser") # We parse HTML in a BeautifulSoup object
img = soup.find("img") # We get the first image of the webpage
img_url = img.get("src") # We get the source of the image
return img_url # And we return it
if __name__ == "__main__":
title = "16 to Life"
nb_recommendations = 10
age_category = "child"
user_choices = {"languages": None,
"duration": None,
"filter": None}
df_recommendations = generate_recommendations(title=title, nb=nb_recommendations, age_category=age_category)
df_recommendations2 = filter_recommendations(df=df_recommendations, choices=user_choices, nb=nb_recommendations)
print(df_recommendations)
print(load_movies().columns.values)
print(df_recommendations.iloc[0]["movie_imdb_link"])
print(generate_recommendations(title=title, nb=nb_recommendations).index)
print(load_recommendations(idx=list(range(51))))
df = load_movies()
idx = list(range(51))
# We return only the movies with an index in 'idx'
print(df.iloc[idx])
Et l'erreur du test
======================================================================
ERROR: test_post_request (src.app.tests.test_views.ResultViewTest.test_post_request)
----------------------------------------------------------------------
Traceback (most recent call last):
File "C:\Users\chris\PROGRAMATION\WildCodeSchool\PROJET_2\movie_recommendations\src\app\tests\test_views.py", line 78, in test_post_request
request = self.client.post(reverse('app:result'), data={
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\chris\PROGRAMATION\WildCodeSchool\PROJET_2\movie_recommendations\venv\Lib\site-packages\django\test\client.py", line 948, in post
response = super().post(
^^^^^^^^^^^^^
File "C:\Users\chris\PROGRAMATION\WildCodeSchool\PROJET_2\movie_recommendations\venv\Lib\site-packages\django\test\client.py", line 482, in post
return self.generic(
^^^^^^^^^^^^^
File "C:\Users\chris\PROGRAMATION\WildCodeSchool\PROJET_2\movie_recommendations\venv\Lib\site-packages\django\test\client.py", line 609, in generic
return self.request(**r)
^^^^^^^^^^^^^^^^^
File "C:\Users\chris\PROGRAMATION\WildCodeSchool\PROJET_2\movie_recommendations\venv\Lib\site-packages\django\test\client.py", line 891, in request
self.check_exception(response)
File "C:\Users\chris\PROGRAMATION\WildCodeSchool\PROJET_2\movie_recommendations\venv\Lib\site-packages\django\test\client.py", line 738, in check_exception
raise exc_value
File "C:\Users\chris\PROGRAMATION\WildCodeSchool\PROJET_2\movie_recommendations\venv\Lib\site-packages\django\core\handlers\exception.py", line 55, in inner
response = get_response(request)
^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\chris\PROGRAMATION\WildCodeSchool\PROJET_2\movie_recommendations\venv\Lib\site-packages\django\core\handlers\base.py", line 197, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\chris\PROGRAMATION\WildCodeSchool\PROJET_2\movie_recommendations\src\app\views.py", line 77, in result
df = utils.load_recommendations(idx)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\chris\PROGRAMATION\WildCodeSchool\PROJET_2\movie_recommendations\src\app\utils.py", line 39, in load_recommendations
return df.iloc[idx]
~~~~~~~^^^^^
File "C:\Users\chris\PROGRAMATION\WildCodeSchool\PROJET_2\movie_recommendations\venv\Lib\site-packages\pandas\core\indexing.py", line 1103, in __getitem__
return self._getitem_axis(maybe_callable, axis=axis)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\chris\PROGRAMATION\WildCodeSchool\PROJET_2\movie_recommendations\venv\Lib\site-packages\pandas\core\indexing.py", line 1653, in _getitem_axis
raise TypeError("Cannot index by location index with a non-integer key")
TypeError: Cannot index by location index with a non-integer key
----------------------------------------------------------------------
Ran 12 tests in 7.122s
FAILED (errors=1)
Destroying test database for alias 'default'...
Process finished with exit code 1
Et le lien du dépot git pour avoir une vision d'ensemble du projet :
https://github.com/Stargate136/movie-recommendations.git
Je ne comprend vraiment pas ou est l'erreur, et j'ai plus beaucoup de temps pour finaliser le projet ... AU SECOUR !!

Thibault houdon
Mentor
Salut Christian !
Alors, je n'ai pas testé le projet en local mais il me semble que l'erreur provient de ton request.session que tu écrases par un dictionnaire.
Ça provoque un problème dans ton fichier utils.py qui n'arrive pas à accéder correctement aux données dans load_recommendations.
L'objet session c'est une instance de SessionBase, dont voici une partie du code source :
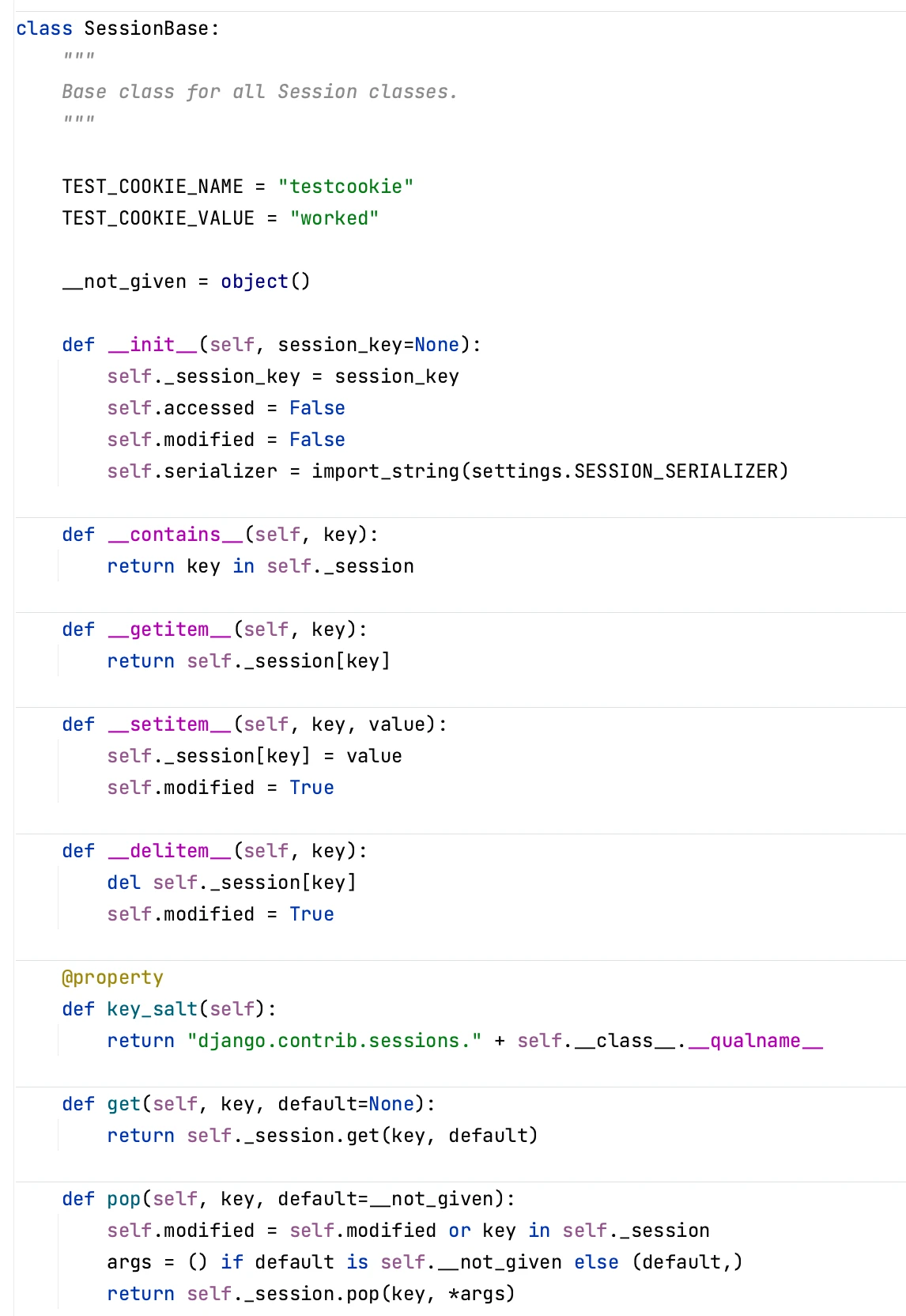
Donc comme tu le vois ce n'est pas un simple dictionnaire, il y a tout un mécanisme caché avec le getitem et setitem qui permet de modifier l'attribut privé self._session.
Donc quand tu fais :
request.session = { # Mocked session data
"title": title,
"nb": nb,
"recommendations_idx": recommendations_idx
}
Tu écrases tout le mécanisme de la classe par un dictionnaire Python classique.
À la place il faudrait définir les clés directement sur l'objet (ce qui appelera en bout de ligne la méthode __setitem__ que tu vois sur le screenshot plus haut, qui défini les clés dans l'attribut self._session de ton instance) :
self.client.session['title'] = "Spider-Man 3"
self.client.session['nb'] = 5
self.client.session['recommendations_idx'] = list(range(51))
self.client.session.save()
Il est possible qu'il y ait d'autres problèmes à d'autres endroits mais je commencerais déjà par vérifier ça.
Tiens-nous au courant et bon courage, on est là pour t'aider ce week-end si tu as besoin :)
Christian Aucane
J'ai modifié mon code avec les lignes que tu m'as donné mais ca ne change rien, toujours le même message d'erreur
Thibault houdon
Mentor
Salut Christian,
Ok alors il faut creuser un peu plus dans ta fonction load_recommendations.
Le problème est ici :
df.iloc[idx]
Rajoutes un try / except à cet endroit ou met un point de debug pour vérifier ce que contient idx quand tu lances ton test.
Parce qu'en fonction de ce qui se trouve dans ta session, idx pourrait ne pas être une liste d'entiers. Par exemple, si la session est vide ou mal initialisée, idx pourrait être None et ça expliquerait ton erreur.
Tu peux aussi faire le même débug en amont dans ta vue :
idx = request.session.get("recommendations_idx")
Pour vérifier à cet endroit si tu récupères bien ce que tu as mis dans ta session.
Christian Aucane
C'est ca mon idx vaut None, dans mon test, ça doit etre un probleme dans la maniere d'enregistrer dans la session peut-être ?
Thibault houdon
Mentor
Oui, je pense vraiment déjà qu'il faut que tu sauvegardes les données dans la session comme je t'ai indiqué dans mon premier message.
Et aussi les sauvegarder avant de faire ta requête, quelque chose comme ça :
def test_post_request(self):
# Test POST request
session = self.client.session
session["title"] = "Spider-Man 3"
session["nb"] = 5
session["recommendations_idx"] = list(range(51))
session.save()
response = self.client.post(reverse('app:result'), data={
"age": "adult",
"languages": ["English"],
"duration": ["1"],
"filter": "genres",
"genres": ["Action"],
})
# Check the returned status code
self.assertEqual(response.status_code, 200)
# Check if the correct template is used
self.assertTemplateUsed(response, 'app/result.html')
# Check if the context data is correctly added
self.assertIn("title", response.context)
self.assertIn("nb", response.context)
self.assertIn("recommended_films", response.context)
Christian Aucane
Ca marche, merci !
Inscris-toi
(c'est gratuit !)

Tu dois créer un compte pour participer aux discussions.
Créer un compte